|
|

|

|
| e-Pub |
Section: New Results
Computer-Assisted Design with Heterogeneous Representations
Patterns from Photograph: Reverse-Engineering Developable Products
Participants: Adrien Bousseau.
Developable materials are ubiquitous in design and manufacturing. Unfortunately, general-purpose modeling tools are not suited to modeling 3D objects composed of developable parts. We propose an interactive tool [13] to model such objects from a photograph (Fig. 4). Users of our system load a single picture of the object they wish to model, which they annotate to indicate silhouettes and part boundaries. Assuming that the object is symmetric, we also ask users to provide a few annotations of symmetric correspondences. The object is then automatically reconstructed in 3D. At the core of our method is an algorithm to infer the 2D projection of rulings of a developable surface from the traced silhouettes and boundaries. We impose that the surface normal is constant along each ruling, which is a necessary property for the surface to be developable. We complement these developability constraints with symmetry constraints to lift the curve network in 3D. In addition to a 3D model, we output 2D patterns enabling to fabricate real prototypes of the object on the photo. This makes our method well suited for reverse engineering products made of leather, bent cardboard or metal sheets.
|
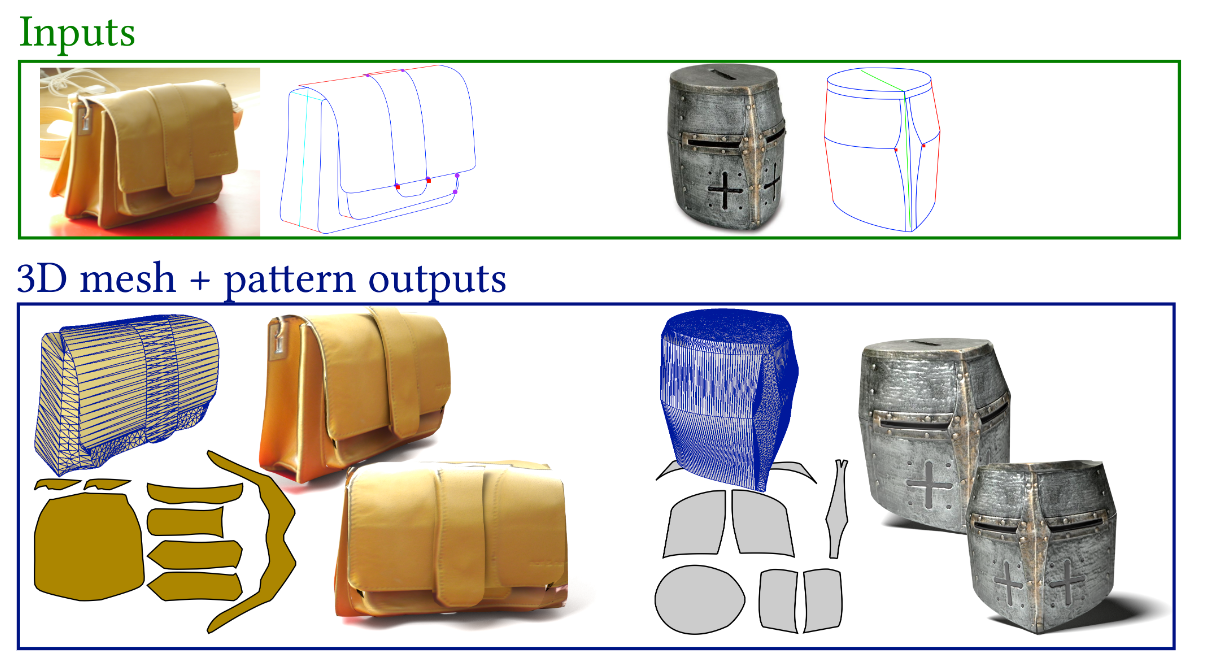
This work is a collaboration with Amélie Fondevilla, Damien Rohmer, Stefanie Hahmann and Marie-Paule Cani from the IMAGINE team at Inria Rhône Alpes. The work was published in the special issue of the journal Computers and Graphics (Elsevier), presented at the Shape Modeling International conference.
SketchSoup: Exploratory Ideation Using Design Sketches
Participants: Adrien Bousseau.
A hallmark of early stage design is a number of quick-and-dirty sketches capturing design inspirations, model variations, and alternate viewpoints of a visual concept. We developed SketchSoup [7], a workflow that allows designers to explore the design space induced by such sketches (Fig. 5). We take an unstructured collection of drawings as input, along with a small number of user-provided correspondences as input. We register them using a multi-image matching algorithm, and present them as a 2D interpolation space. By morphing sketches in this space, our approach produces plausible visualizations of shape and viewpoint variations despite the presence of sketch distortions that would prevent standard camera calibration and 3D reconstruction. In addition, our interpolated sketches can serve as inspiration for further drawings, which feed back into the design space as additional image inputs. SketchSoup thus fills a significant gap in the early ideation stage of conceptual design by allowing designers to make better informed choices before proceeding to more expensive 3D modeling and prototyping. From a technical standpoint, we describe an end-to-end system that judiciously combines and adapts various image processing techniques to the drawing domain – where the images are dominated not by color, shading and texture, but by sketchy stroke contours.
|
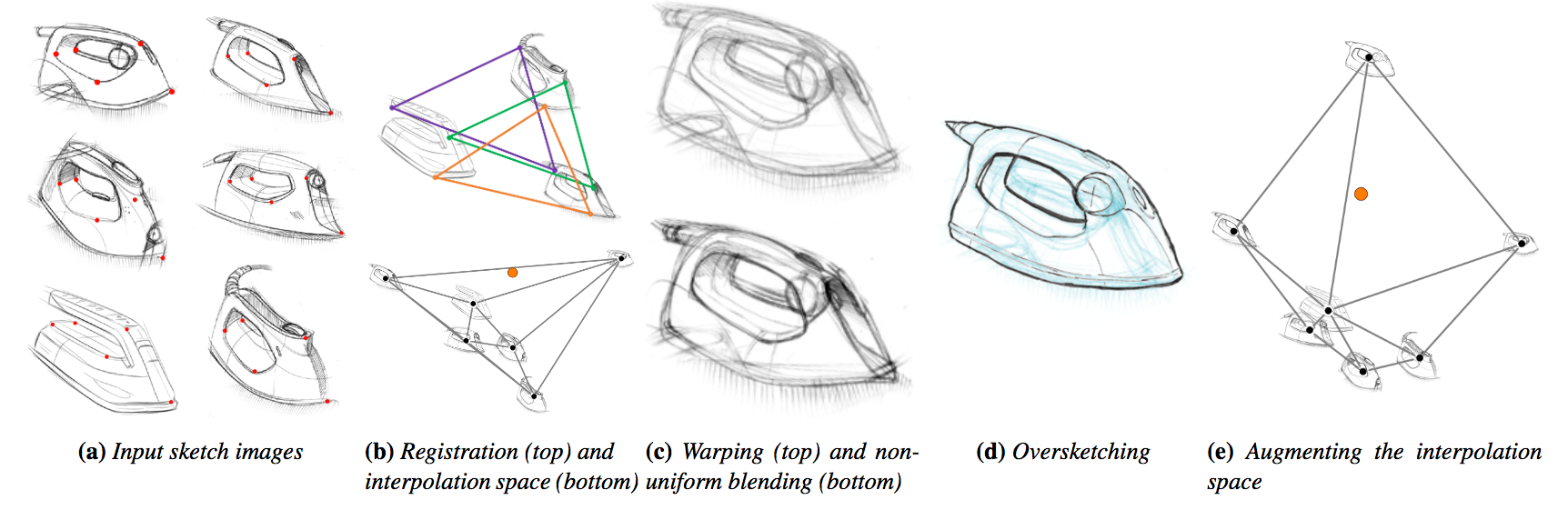
This work is a collaboration with Rahul Arora and Karan Singh from Toronto University (Canada) and Ishan Darolia and Vinay P. Namboodiri from IIT Kampur (India). The work was published in the journal Computer Graphics Forum and presented at the Eurographics conference.
Photo2ClipArt: Image Abstraction and Vectorization Using Layered Linear Gradients
Participants: Adrien Bousseau, Jean-Dominique Favreau.
We present a method to create vector cliparts from photographs [8]. Our approach aims at reproducing two key properties of cliparts: they should be easily editable, and they should represent image content in a clean, simplified way. We observe that vector artists satisfy both of these properties by modeling cliparts with linear color gradients, which have a small number of parameters and approximate well smooth color variations. In addition, skilled artists produce intricate yet editable artworks by stacking multiple gradients using opaque and semi-transparent layers. Motivated by these observations, our goal is to decompose a bitmap photograph into a stack of layers, each layer containing a vector path filled with a linear color gradient. We cast this problem as an optimization that jointly assigns each pixel to one or more layer and finds the gradient parameters of each layer that best reproduce the input. Since a trivial solution would consist in assigning each pixel to a different, opaque layer, we complement our objective with a simplicity term that favors decompositions made of few, semi-transparent layers. However, this formulation results in a complex combinatorial problem combining discrete unknowns (the pixel assignments) and continuous unknowns (the layer parameters). We propose a Monte Carlo Tree Search algorithm that efficiently explores this solution space by leveraging layering cues at image junctions. We demonstrate the effectiveness of our method by reverse-engineering existing cliparts and by creating original cliparts from studio photographs.
|
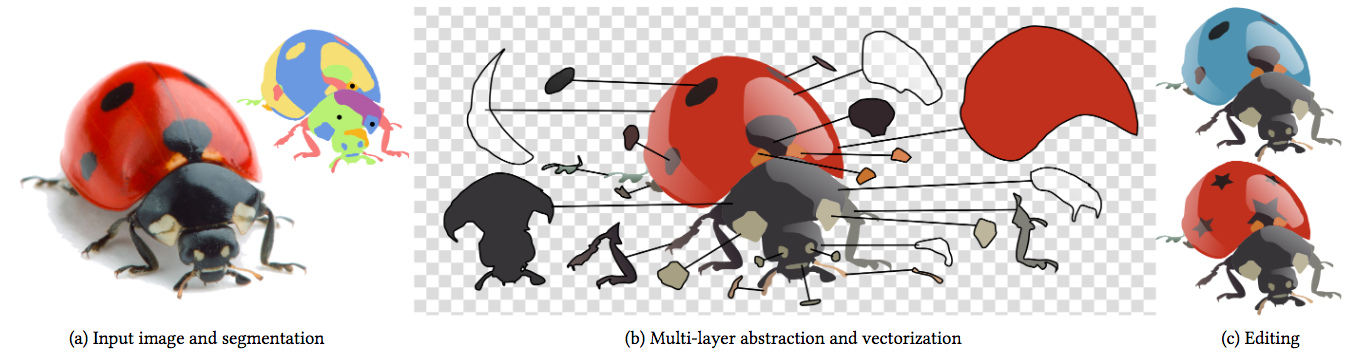
This work is a collaboration with Florent Lafarge from the Titane team at Inria Sophia Antipolis. The work was published in the journal ACM Transactions on Graphics and presented at the SIGGRAPH Asia conference.
Data Collection and Analysis of Industrial Design Drawings
Participants: Yulia Gryaditskaya (post-doctoral researcher), Adrien Bousseau (permanent researcher) and Fredo Durand (visiting researcher).
The goal of this project is to collect a dataset of industrial design drawings uniquely matched to a 3D geometry and accompanied by metadata such as each stroke position, time of creation and pressure. We are interested in creation of a classification of lines the designers use and analysis of their relation to the underlying shape. We are further interested in evaluation of correlation between the presence of construction techniques and perspective accuracy of the sketch. We are planning to provide a ground-truth labelling guided by experience of professional designers which will enable development of multiple algorithms, such as sketch beautification and vectorization, style transfer and 3D inference.
This work is a collaboration with Mark Sypesteyn, Jan Willem Hoftijzer and Sylvia Pont from TU Delft, Netherlands.
What You Sketch Is What You Get: 3D Sketching using Multi-View Deep Volumetric Prediction
Participants: Johanna Delanoy, Adrien Bousseau
Drawing is the most direct way for people to express their visual thoughts. However, while humans are extremely good at perceiving 3D objects from line drawings, this task remains very challenging for computers as many 3D shapes can yield the same drawing. Existing sketch-based 3D modeling systems rely on heuristics to reconstruct simple shapes, require extensive user interaction, or exploit specific drawing techniques and shape priors. Our goal is to lift these restrictions and offer a minimal interface to quickly model general 3D shapes with contour drawings. While our approach can produce approximate 3D shapes from a single drawing, it achieves its full potential once integrated into an interactive modeling system, which allows users to visualize the shape and refine it by drawing from several viewpoints. At the core of our approach is a deep convolutional neural network (CNN) that processes a line drawing to predict occupancy in a voxel grid. The use of deep learning results in a flexible and robust 3D reconstruction engine that allows us to treat sketchy bitmap drawings without requiring complex, hand-crafted optimizations. While similar architectures have been proposed in the computer vision community, our originality is to extend this architecture to a multiview context by training an updater network that iteratively refines the prediction as novel drawings are provided.
This work is a collaboration with Mathieu Aubry from Ecole des Ponts ParisTech and Alexei Efros and Philip Isola from UC Berkeley. It is supported by the CRISP Inria associate team.
Flatenning videos for stylization
Participants: Johanna Delanoy, Adrien Bousseau
Traditional 2D animation exhibits a very specific sense of motion where objects seems to move in a 2D world. Existing stylization methods for videos use the optical flow to ensure temporal consistency of the stylization process. Although the method produces very convincing results, the resulting video often looks like a 3D textured scene instead of a 2D animation. In this project, we propose to transform the input video into a new one with a simplified motion. To achieve this effect, we approximate the motion with 2D rigid patches (rigid motion and scaling): each frame is segmented into rigid motion patches that provide a good approximation of the initial motion. The final sequence exhibits a flattened motion and can be used in any stylization process. This produces a stylized video that has a feeling of 2D motion and is more similar to traditional animation.
This work is a collaboration with Aaron Hertzmann from Adobe Research.